Visualizing Kernels and Feature Maps in Deep Learning Model (CNN)

CNN (Convolutional Neural Network)
- เป็นโครงสร้างภายใน Deep Learning Model ที่ใช้แนวคิดของ Convolution ในการทำงานกับข้อมูล 2 มิติ เช่น Image Data ซึ่งแต่ละ Pixel ของ Image จะมีความสัมพันธ์กันในเชิงพื้นที่ (Spatial Relationship)
- ประกอบด้วย Kernel และผลลัพธ์จากการกระทำทางคณิตศาสตร์ของ Kernel กับ Input Image ที่เรียกว่า Activation Map หรือ Feature Map โดยทั้ง Kernel และ Feature Map นั้นสามารถแสดงผลได้ด้วยภาพ
2D Convolutions Concept

2D Convolution
- เป็นการนำ Matrix ขนาดเล็ก ของ Weight หรือที่เรียกว่า Kernel มา Slide ไปบน 2D Input Image (สีฟ้าด้านบนซ้ายมือ) โดยขณะที่มีการทาบ Kernel บน Input Image มันจะคูณค่าแต่ละ Pixel ของ Input Image กับ Kernel แล้วนำผลลัพธ์ทั้งหมดมาบวกกันเป็น 1 จุด Pixel ของ Feature Map (สีเขียวขวามือ)
- มีการสร้าง Feature Map ขึ้นมาด้วยการนำ Kernel Slide ไปบน Input Image จะใช้ Parameter น้อยกว่า Fully Connected Layer
Padding
- ตามภาพด้านบน ขณะที่มีการ Slide Kernel เราจะเห็นว่า Pixel ตรงขอบภาพสีฟ้าจะไม่มีทางอยู่ตรงกลาง Kernel ตอนที่มันทาบลงไป เพราะเราไม่สามารถขยาย Kernel ให้เลยออกไปนอกขอบของภาพ จึงทำให้ Feature Map ที่ได้มีขนาดเล็กกว่า Input Image ครับ
- ดังนั้น เพื่อจะทำให้ Feature Map มีขนาดเท่ากับ Input Image และ Pixel ที่ขอบภาพอยู่ตรงกลาง Kernel ตอนที่มันทาบลงไป เราจะต้องมีการทำ Padding โดยการเสริมกรอบด้วยการเติม 0 (Zero Padding) รอบๆ ภาพเดิม

Striding
- เป็นกระบวนการในการทำ Convolution โดยการเลื่อนแผ่น Kernel ไปบน Input Image ซึ่งโดย Default ของ Convolution แล้ว Stride จะมีค่าเท่ากับ 1 คือจะมีการเลื่อน Kernel ไปบน Input Image ครั้งละ 1 Pixel
- เราสามารถลดขนาดของภาพที่แต่ละ Pixel มีความสัมพันธ์กันในเชิงพื้นที่ได้โดยการเพิ่มค่า Stride ซึ่งเมื่อมีการกำหนดค่า Stride มากขึ้น จะทำให้การเลื่อมกันของ Kernel ตอนที่มีการทาบกับ Input Image และขนาดของ Feature Map ลดลง
- เมื่อกำหนด Stride เท่ากับ 2 แล้ว Kernel ขนาด 3x3 จะถูก Slide ข้าม Pixel ของ Input Image ขนาด 5x5 ทีละ 2 Pixel ทำให้ได้ Feature Map ขนาด 2x2 ดังภาพด้านล่าง

Pooling
- นอกจากการลดขนาดของภาพด้วยการเพิ่มค่า Stride โดยการ Slide Kernel ข้าม Pixel ของ Input Image ตามระยะทางที่กำหนดแล้ว ยังมีอีกวิธีหนึ่งในการลดขนาดของภาพ คือการทำ Max Pooling หรือ Average Pooling โดย Pooling จะเป็นกระบวนการทำงานภายนอก CNN Layer

Max Pooling หรือ Average Pooling
- จะเป็นการเลือกตัวแทนของภาพด้วยการหาค่ามากที่สุด หรือค่าเฉลี่ยจาก Pixel ใน Window ตามขนาดที่กำหนด เช่น ขนาด 2x2 ซึ่งจะทำให้มีการลดขนาดของภาพลงได้ครึ่งหนึ่งดังตัวอย่างด้านบน
Multi-channel
- เป็นการจัดการกับ Input Image แบบ 1 Channel เช่น ภาพแบบ Grayscale แต่บ่อยครั้งที่ Input Image ของเราจะเป็นภาพสี แบบ 3 Channel (โดยทั่วไปจำนวน Channel ของ Input Image จะเพิ่มขึ้นเมื่อมันถูกส่งเข้าสู่ชั้น CNN Layer ที่ลึกขึ้น)

- เพื่อจะจัดการกับ Input Image แบบ 3 Channel อย่างเช่นภาพสีในระบบ RGB เราจะต้องใช้ Kernel จำนวน 3 ตัว ในการ Slide ไปบน Input Image แต่ละ Channel ซึ่งเราเรียก Kernel ทั้ง 3 ตัวว่า Filter (ในที่นี้ 1 Filter ประกอบด้วย Kernel 3 Kernel)

- Feature Map แต่ละ Version ขนาด 3x3 ที่เกิดจากการ Slide Kernel ไปบน Input Channel ขนาด 5x5 จะถูกนำมารวมกันเป็น Output Channel 1 Channel เพื่อจะส่งต่อไปยัง Neural Network Layer ถัดไป

- ซึ่ง Output Channel จะถูกนำมาบวกกับ Bias ในขั้นตอนสุดท้ายของกระบวนการทำ Convolution

- เพื่อจะสร้าง Output Channel 1 Channel ดังภาพด้านบน เราจะต้องใช้ Filter 1 Filter ซึ่งแต่ละ Filter ก็จะประกอบด้วยจำนวน Kernel 3 Kernel ดังนั้นในกรณีที่ต้องการสร้าง Output Channel หลาย Channel เราจะต้องมีจำนวน Filter หลาย Filter
Visualizing CNN
สำหรับผู้อ่านที่มี GPU สามารถ Config การใช้งาน ด้วยคำสั่งต่อไปนี้
!nvidia-smi -Limport tensorflow as tf
tf.__version__config = tf.compat.v1.ConfigProto()
config.gpu_options.allow_growth = True
sess = tf.compat.v1.Session(config=config)
print( 'Tensorflow Version:', tf.__version__)
print("GPU Available::", tf.config.list_physical_devices('GPU'))
Import Library และกำหนดค่า Parameter ที่จำเป็น
from tensorflow.python.keras.layers import Dense, Flatten, Conv2D, Dropout, Activation, BatchNormalization, MaxPool2Dfrom tensorflow.python.keras.models import Sequential
from tensorflow.keras.optimizers import Adam
import tensorflow as tf
from tensorflow.keras.datasets import fashion_mnist
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.callbacks import ModelCheckpoint
from tensorflow.python.keras.models import load_model
from sklearn.model_selection import train_test_split
import numpy as np
import matplotlib.pyplot as plt
import plotly.graph_objs as go
from plotly import tools
import plotly
import cv2
from keras.callbacks import ModelCheckpoint
%matplotlib inlineแต่ก่อนอื่นเราจะอ่านไฟล์ภาพ มาทดลองนำเข้า CNN Model ที่ยังไม่ถูก Train ตามขั้นตอน ดังนี้
อ่านไฟล์ภาพ
cat = cv2.imread('cat.jpg')
cat.shapeแปลงระบบสีจาก BGR ซึ่งเป็นค่า Default ของ OpenCV Library เป็น RGB
cat = cv2.cvtColor(cat, cv2.COLOR_RGB2BGR)Plot ภาพ
plt.figure(dpi=100)
plt.imshow(cat)
cat.shape
Create a Model with 2D CNN Layer
- นิยาม Model แบบ 2D Convolution โดยรับ Input Image ขนาด 1,440x1,080 Pixel แบบ 3 Channel โดยมี Filter ขนาด 3x3 จำนวน 3 Filter เพื่อนำไป Slide บน Input Image ของแต่ละ Channel

- จากภาพด้านบน Model ของเราจะมีจำนวน Parameter เท่ากับ (Filter + Bias) 3x3x3x3 + 3 = 84 Parameter
model = Sequential()
model.add(Conv2D(3, # number of filter layers
(3, # y dimension of kernel
3), # x dimension of kernel
input_shape=cat.shape))model.summary()

- ทดลองขยายมิติของภาพจาก 3 มิติเป็น 4 มิติ เพื่อเตรียมนำเข้า Predict Function
cat_batch = np.expand_dims(cat,axis=0)
cat_batch.shape
- ทดลอง predict Model โดยใช้ค่า Weight และ Bias แบบสุ่มในตอนเริ่มต้น โดยยังไม่มีการ Train Model
conv_cat = model.predict(cat_batch)
conv_cat.shape
เนื่องจากเรามีการนิยาม Model โดยกำหนดจำนวน Filter ไว้ที่ 3 Filter ดังนั้นจึงทำให้ได้ Output Channel ขนาด 1,438x1,078 ทั้งหมด 3 Channel ซึ่งขนาดของ Output Channel จะลดลงจากเดิม 1,440x1,080 Pixel เนื่องมาจาก มีการ Slide Kernel ขนาด 3x3 ไปบน Input Image โดยไม่มีการทำ Padding
นิยาม visualize_cat Function ที่รับภาพเป็น Matrix, ขยายภาพเป็น 4 มิติ แล้ว Predict ภาพ ก่อนจะหดให้เหลือ 3 มิติเท่าเดิมเพื่อจะ Plot ภาพต่อไป
def visualize_cat(model, cat):
cat_batch = np.expand_dims(cat,axis=0)
conv_cat = model.predict(cat_batch)
conv_cat = np.squeeze(conv_cat, axis=0)
print(conv_cat.shape)
conv_cat = cv2.cvtColor(conv_cat, cv2.COLOR_RGB2BGR)
plt.imshow(conv_cat)Plot ภาพ
visualize_cat(model, cat)
นิยาม Model แบบ 2D Convolution โดยรับ Input Image ขนาด 1,440x1,080 Pixel แบบ 3 Channel โดยมี Filter ขนาด 10x10 จำนวน 3 Filter เพื่อนำไป Slide บน Input Image แต่ละ Channel
model = Sequential()
model.add(Conv2D(3,(10, 10), input_shape=cat.shape))
model.summary()
Plot ภาพ
visualize_cat(model, cat)
นิยาม Model แบบ 2D Convolution โดยรับ Input Image ขนาด 1,440x1,080 Pixel แบบ 3 Channel โดยมี Filter ขนาด 3x3 จำนวน 1 Filter
model = Sequential()
model.add(Conv2D(1,(3,3),input_shape=cat.shape))
model.summary()
นิยาม visualize_cat_one_channel Function ที่รับภาพเป็น Matrix ขยายภาพเป็น 4 มิติ แล้ว Predict ภาพ ก่อนจะหดให้เหลือ 2 มิติ เพื่อจะ Plot ภาพ แบบ 1 Channel ต่อไป
def visualize_cat_one_channel(model, cat):
cat_batch = np.expand_dims(cat,axis=0)
conv_cat2 = model.predict(cat_batch)
conv_cat2 = np.squeeze(conv_cat2, axis=0)
conv_cat2 = conv_cat2.reshape(conv_cat2.shape[:2])
plt.imshow(conv_cat2)Plot ภาพ
visualize_cat_one_channel(model, cat)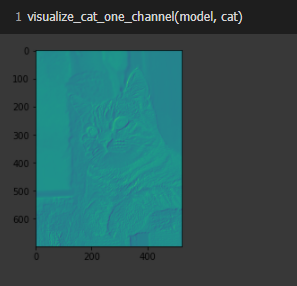
นิยาม Model แบบ 2D Convolution โดยรับ Input Image ขนาด 1,440x1,080 Pixel แบบ 3 Channel โดยมี Filter ขนาด 20x20 จำนวน 1 Filter
model = Sequential()
model.add(Conv2D(1,(20,20),input_shape=cat.shape))
model.summary()
Plot ภาพ
visualize_cat_one_channel(model, cat)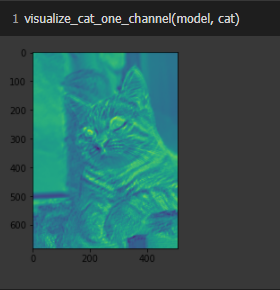
นิยาม Model แบบ 2D Convolution โดยรับ Input Image ขนาด 1,440x1,080 Pixel แบบ 3 Channel โดยมี Filter ขนาด 20x20 จำนวน 1 Filter และเพิ่ม ReLu Activation Function
model = Sequential()
model.add(Conv2D(1,(20,20),input_shape=cat.shape))model.add(Activation('relu'))
model.summary()

Plot ภาพ
visualize_cat_one_channel(model, cat)
นิยาม Model แบบ 2D Convolution โดยรับ Input Image ขนาด 1,440x1,080 Pixel แบบ 3 Channel โดยมี Filter ขนาด 3x3 จำนวน 1 Filter และเพิ่ม Max Pooling ขนาด 5x5
model = Sequential()
model.add(Conv2D(1,(3,3),input_shape=cat.shape))model.add(MaxPooling2D(pool_size=(5,5)))
model.summary()

Plot ภาพ
visualize_cat_one_channel(model, cat)
นิยาม Model แบบ 2D Convolution โดยรับ Input Image ขนาด 1,440x1,080 Pixel แบบ 3 Channel โดยมี Filter ขนาด 3x3 จำนวน 1 Filter เพิ่ม ReLu Activation Function และ Max Pooling ขนาด 5x5
model = Sequential()
model.add(Conv2D(1,(3,3),input_shape=cat.shape))model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(5,5)))

Plot ภาพ
visualize_cat_one_channel(model, cat)
นิยาม Model แบบ 2D Convolution, ReLu Activation Function และ Max Pooling อย่างละ 2 Layer
model = Sequential()
model.add(Conv2D(1,(3,3),input_shape=cat.shape))model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(3,3)))model.add(Conv2D(1,(3,3)))model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(3,3)))
model.summary()

Plot ภาพ
visualize_cat_one_channel(model, cat)
Fashion-MNIST Model
- Fashion-MNIST เป็น Dataset ที่เป็นภาพเสื้อผ้า กระเป๋า และรองเท้า ขนาด 28x28 Pixel แบบ Grayscale แบ่งเป็นข้อมูล Train 60,000 ภาพ และข้อมูล Test อีก 10,000 ภาพ รวมทั้งหมด 10 ประเภท โดยมีการกำหนด Label ตั้งแต่ 0–9 ดังนี้
0: T-shirt/top
1: Trouser
2: Pullover
3: Dress
4: Coat
5: Sandal
6: Shirt
7: Sneaker
8: Bag
9: Ankle boot
เราจะ Train Deep Learning Model แบบ CNN เพื่อ Classify ภาพ 10 ประเภท ของ Fashion-MNIST Dataset แล้วดึง Kernel และ Feature Map ออกมาแสดงผลด้วยภาพ ตามขั้นตอนดังต่อไปนี้
กำหนดค่า Parameter ที่จำเป็น
IMG_ROWS = 28
IMG_COLS = 28
NUM_CLASSES = 10
TEST_SIZE = 0.2
RANDOM_STATE = 99BATCH_SIZE = 128
Load Dataset
(train_data, y), (test_data, y_test) = fashion_mnist.load_data()print("Fashion MNIST train - rows:",train_data.shape[0]," columns:", train_data.shape[1], " rows:", train_data.shape[2])
print("Fashion MNIST test - rows:",test_data.shape[0]," columns:", test_data.shape[1], " rows:", train_data.shape[2])

for i in range(9):
plt.subplot(330 + 1 + i)
plt.imshow(train_data[i], cmap=plt.get_cmap('gray'))
plt.show()
ขยายมิติของ Dataset
print(train_data.shape, test_data.shape)train_data = train_data.reshape((train_data.shape[0], 28, 28, 1))
test_data = test_data.reshape((test_data.shape[0], 28, 28, 1))print(train_data.shape, test_data.shape)

ทำ Scaling
train_data = train_data / 255.0
test_data = test_data / 255.0เข้ารหัสผลเฉลยแบบ One-hot Encoding
y = to_categorical(y)
y_test = to_categorical(y_test)print(y.shape, y_test.shape)
y[:10]

แบ่งข้อมูลสำหรับ Train และ Validate โดยการสุ่มในสัดส่วน 80:20
X_train, X_val, y_train, y_val = train_test_split(train_data, y, test_size=TEST_SIZE, random_state=RANDOM_STATE)X_train.shape, X_val.shape, y_train.shape, y_val.shape

นิยาม Function สำหรับ Plot Loss และ Accuracy
def create_trace(x,y,ylabel,color):
trace = go.Scatter(
x = x,y = y,
name=ylabel,
marker=dict(color=color),
mode = "markers+lines",
text=x
)
return trace
def plot_accuracy_and_loss(train_model):
hist = train_model.history
acc = hist['accuracy']
val_acc = hist['val_accuracy']
loss = hist['loss']
val_loss = hist['val_loss']
epochs = list(range(1,len(acc)+1))
trace_ta = create_trace(epochs,acc,"Training accuracy", "Green")
trace_va = create_trace(epochs,val_acc,"Validation accuracy", "Red")
trace_tl = create_trace(epochs,loss,"Training loss", "Blue")
trace_vl = create_trace(epochs,val_loss,"Validation loss", "Magenta")
fig = tools.make_subplots(rows=1,cols=2, subplot_titles=('Training and validation accuracy',
'Training and validation loss'))
fig.append_trace(trace_ta,1,1)
fig.append_trace(trace_va,1,1)
fig.append_trace(trace_tl,1,2)
fig.append_trace(trace_vl,1,2)
fig['layout']['xaxis'].update(title = 'Epoch')
fig['layout']['xaxis2'].update(title = 'Epoch')
fig['layout']['yaxis'].update(title = 'Accuracy', range=[0,1])
fig['layout']['yaxis2'].update(title = 'Loss', range=[0,1]) plotly.offline.iplot(fig, filename='accuracy-loss')
นิยามวิธีการทำ Image Augmentation
datagen = ImageDataGenerator(
rotation_range=0.05, #Randomly rotate images in the range
zoom_range = 0.2, # Randomly zoom image
width_shift_range=0.1, #Randomly shift images horizontally
height_shift_range=0.1, #Randomly shift images vertically
shear_range=0.05 #Randomly shear images
)datagen.fit(X_train)
นิยาม Model
model = Sequential()#1. CNN LAYER
model.add(Conv2D(filters = 32, kernel_size = (3,3), padding = 'Same', input_shape=(28, 28, 1), name = 'conv2d1'))
model.add(BatchNormalization(name = 'batch_norm1'))
model.add(Activation("relu", name = 'relu1'))
model.add(Dropout(0.3, name = 'dropout1'))#2. CNN LAYER
model.add(Conv2D(filters = 32, kernel_size = (3,3), padding = 'Same', name = 'conv2d2'))
model.add(BatchNormalization(name = 'batch_norm2'))
model.add(Activation("relu", name = 'relu2'))model.add(MaxPool2D(pool_size=(2, 2), name = 'maxpool2d1'))
model.add(Dropout(0.3, name = 'dropout2'))#3. CNN LAYER
model.add(Conv2D(filters = 64, kernel_size = (3,3), padding = 'Same', name = 'conv2d3'))
model.add(BatchNormalization(name = 'batch_norm3'))
model.add(Activation("relu", name = 'relu3'))
model.add(Dropout(0.3, name = 'dropout3'))#4. CNN LAYER
model.add(Conv2D(filters = 64, kernel_size = (3,3), padding = 'Same', name = 'conv2d4'))
model.add(BatchNormalization(name = 'batch_norm4'))
model.add(Activation("relu", name = 'relu4'))model.add(MaxPool2D(pool_size=(2, 2), name = 'maxpool2d2'))
model.add(Dropout(0.3, name = 'dropout4'))
#FULLY CONNECTED LAYER
model.add(Flatten(name = 'flatten1'))
model.add(Dense(256, name = 'dense1'))
model.add(BatchNormalization(name = 'batch_norm5'))
model.add(Activation("relu", name = 'relu5'))
model.add(Dropout(0.30, name = 'dropout5'))#OUTPUT LAYER
model.add(Dense(10, activation='softmax', name = 'dense2'))
Compile Model
optimizer = Adam()
model.compile(optimizer = optimizer, loss = "categorical_crossentropy", metrics=["accuracy"]นิยามการทำ Checkpoint เพื่อ Save Model เฉพาะ Epoch ที่ค่า val_loss น้อยกว่ารอบก่อนหน้า
filepath="weights.best.hdf5"
checkpoint = ModelCheckpoint(filepath, monitor='val_loss', verbose=1, save_best_only=True, mode='min')
callbacks_list = [checkpoint]Train Model
NO_EPOCHS = 200
history = model.fit_generator(datagen.flow(X_train, y_train, batch_size=BATCH_SIZE),
shuffle=True,
epochs=NO_EPOCHS, validation_data = (X_val, y_val),
verbose = 1, steps_per_epoch=X_train.shape[0] // BATCH_SIZE,
callbacks=callbacks_list)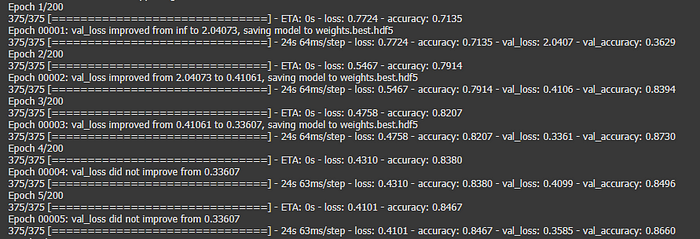

Plot Loss และ Accuracy
plot_accuracy_and_loss(history)
Load Weight ของ Model ที่ค่า val_loss น้อยที่สุด
predict_model = load_model(filepath)Evaluation
score = predict_model.evaluate(test_data, y_test,verbose=0)
print("Test Loss:",score[0])
print("Test Accuracy:",score[1])
Visualizing Kernel
เราสามารถเลือก Kernel และ Feature Map ตาม Layer ต่างๆ ของ Model จากชื่อ Layer หรือระบุ Layer ที่ต้องการโดยใช้ Index
predict_model.summary()

Kernel และ Bias จะอยู่ที่ CNN Layer เท่านั้น ดังนั้นเราจึงต้องดึงมันออกมาจาก Layer ที่มี String “conv” เป็นส่วนหนึ่งของชื่อ Layer ซึ่งเราได้กำหนดไว้ตอนนิยาม Model
kernel_bias = []
for layer in predict_model.layers:
if 'conv' not in layer.name:
continue
kernels, biases = layer.get_weights()
kernel_bias.append([kernels, biases])
print(layer.name, kernels.shape)
จากภาพด้านบน Kernel ภายใน CNN Layer จะถูกเก็บเป็น Matrix ขนาด 4 มิติ ที่ประกอบด้วย Kernel Size (3x3) x จำนวน Input Channel x จำนวน Filter
ดึงมาเฉพาะ Kernel ใน CNN Layer ที่ 1 มาแสดง
kernels, biases = kernel_bias[0]kernels.shape, biases.shape

ทำ Scaling ให้ค่าของ Kernel อยู่ในช่วง 0–1 เพื่อจะแสดงผลด้วยภาพ
k_min, k_max = kernels.min(), kernels.max()
kernels = (kernels - k_min) / (k_max - k_min)แสดงภาพ Kernel ทั้งหมด 32 Kernel จาก CNN Layer ที่ 1 โดยจุด (สี่เหลี่ยม) ที่มืด หมายถึงค่า Weight ที่เล็ก และจุดที่สว่างกว่าแสดงถึงค่า Weight ที่ใหญ่กว่า
n_kernels, ix = 32, 1
for i in range(n_kernels):
f = kernels[:, :, :, i]
for j in range(1):
ax = plt.subplot(8, 4, ix)
ax.set_xticks([])
ax.set_yticks([])
pyplot.imshow(f[:, :, j], cmap='gray')
ix += 1
plt.savefig('filter.jpeg', dpi=200)
Visualizing Feature Map
- เราจะแสดงภาพ Feature Map ที่ถูกสร้างขึ้นด้วยการนำ Input Image มา Predict กับ Fashion-MNIST Model ซึ่งมีการ Train มาก่อน ตามขั้นตอนดังต่อไปนี้
นิยาม Model โดยกำหนดให้ดึง Feature Map ออกมาจาก CNN Layer ที่ 1
model = Model(inputs=predict_model.inputs, outputs=predict_model.layers[0].output)
model.summary()
ดึงภาพ 1 ภาพ จาก Fashion-MNIST Dataset
img = X_train[10:11]Predict Model
feature_maps = model.predict(img)feature_maps.shape

แสดงภาพ Feature Map จาก CNN Layer ที่ 1 ทั้งหมด 32 Feature Map
ix = 1
for _ in range(8):
for _ in range(4):
ax = plt.subplot(8, 4, ix)
ax.set_xticks([])
ax.set_yticks([])
plt.imshow(feature_maps[0, :, :, ix-1], cmap='gray')
ix += 1
plt.savefig('feature_map.jpeg', dpi=300)
นิยาม Model โดยกำหนดให้ดึง Feature Map ออกมาจาก ReLu Layer ที่ 1
model = Model(inputs=predict_model.inputs, outputs=predict_model.layers[2].output)
model.summary()
Predict Model
feature_maps = model.predict(img)feature_maps.shape

แสดงภาพ Feature Map จาก ReLu Layer ที่ 1 ทั้งหมด 32 Feature Map
ix = 1
for _ in range(8):
for _ in range(4):
ax = plt.subplot(8, 4, ix)
ax.set_xticks([])
ax.set_yticks([])
plt.imshow(feature_maps[0, :, :, ix-1], cmap='gray')
ix += 1
plt.savefig('feature_map.jpeg', dpi=300)
นิยาม Model โดยกำหนดให้ดึง Feature Map ออกมาจาก CNN Layer ที่ 2
model = Model(inputs=predict_model.inputs, outputs=predict_model.layers[4].output)
model.summary()
Predict Model
feature_maps = model.predict(img)feature_maps.shape

แสดงภาพ Feature Map จาก CNN Layer ที่ 2 ทั้งหมด 32 Feature Map
ix = 1
for _ in range(8):
for _ in range(4):
ax = plt.subplot(8, 4, ix)
ax.set_xticks([])
ax.set_yticks([])
plt.imshow(feature_maps[0, :, :, ix-1], cmap='gray')
ix += 1
plt.savefig('feature_map.jpeg', dpi=300)
- นิยาม Model โดยกำหนดให้ดึง Feature Map ออกมาจาก Maxpool Layer ที่ 2
model = Model(inputs=predict_model.inputs, outputs=predict_model.layers[16].output)
model.summary()

Predict Model
feature_maps = model.predict(img)feature_maps.shape

แสดงภาพ Feature Map จาก Maxpool Layer ที่ 2 ทั้งหมด 64 Feature Map
ix = 1
for _ in range(8):
for _ in range(8):
ax = plt.subplot(8, 8, ix)
ax.set_xticks([])
ax.set_yticks([])
plt.imshow(feature_maps[0, :, :, ix-1], cmap='gray')
ix += 1
plt.savefig('feature_map.jpeg', dpi=300)
- จากภาพตัวอย่างของ Feature Map ทั้ง 4 ตัวอย่าง จะเห็นได้ว่า Feature Map ที่อยู่ใกล้กับ Input ของ Model จะจับรายละเอียดของภาพได้มาก แต่เมื่อมันถูกประมวลผลใน Layer ที่ลึกลงไป Feature Map จะแสดงรายละเอียดของภาพน้อยลง ทำให้เราไม่สามารถตีความจากภาพได้มากนัก
- อย่างไรก็ตาม รูปแบบของ Feature Map ดังกล่าวก็เป็นสิ่งที่เราคาดการณ์ว่าจะเกิดขึ้นกับ CNN Model ซึ่งพยายามเรียนรู้ที่จะแปลงข้อมูลที่มีความสัมพันธ์เชิงพื้นที่ไปสู่ข้อมูลที่มีความเป็น Abstract/Concept คือ มีการลดรายละเอียดของภาพ แต่เพิ่มระดับของสารสนเทศ (Height Level Information) โดยอัตโนมัติในขณะที่มีการ Train Model